


Ready to kickstart your next big project?
Let's innovate together.
Although REST APIs form a large part of the web-service based applications prevalent today, it comes with certain limitations as the use cases evolve and numerous security, architectural, and performance requirements need to be taken care of while designing the system for scaling and reliability.
Developing software projects for private WAN and organisations with high security and regulatory requirements requires both public internet facing and private cloud facing applications. This often comes part and parcel with numerous non functional requirements that put restrictions not only on the tech stack, but also on the overall architecture of the application.
Facts to Consider
1. Data is often stored on legacy on-premise data centres that cannot be moved to the cloud. These data centres often have limited bandwidth and have high latency due to physical resource constraints and costs.
2. Due to their nature, applications on either network may go through unplanned downtime and maintenance causing the other side to stop functioning.
3. Some processes may require multiple sub processes involving email or PDF generation, process batch jobs, interface with other 3rd party or black box systems that take additional time, and a simple HTTP REST call isn’t enough to manage a delayed response.
4. Gathering data for log processing, data analytics, and audit logging should ideally not have a side effect on the performance of the overall system.
Choosing a Messaging Broker
With a number of open source messaging options available, choosing the right message broker for an application largely depends on the business case of the application. Let’s compare two popular messaging brokers: RabbitMQ and Kafka.
RabbitMQ
- ‘Traditional’ messaging broker that supports legacy protocols like amql0.9 and amqp1.0 .
- Simple to understand and use for applications requiring acknowledgment based message delivery queues, dead letter exchanges for retrying consumers, configurations for high availability, reliability, and security.
- Has built-in plugins for management, clustering, and distributed application setup.
- Easy to understand, use, and deploy.
- Typical use-cases: fine-grain consistency control/guarantees on a per-message basis, P2P publish/subscribe messaging, support for legacy messaging protocols, queue/exchange federation, shovelling.
Kafka
- Relatively newer technology, Kafka is designed for high volume publish-subscribe messages and streams, meant to be durable, fast, and scalable.
- Opposite to RabbitMQ, Kafka retains the messages like a time series persistent database.
- Supports a large number of consumers and retain large amounts of data with very little overhead.
- Typical use-cases: website activity tracking, metrics, log aggregation, stream processing, event Sourcing, commit logs.
Getting Started with RabbitMQ using Docker
RabbitMQ is an open source light-weight message broker written in Erlang with client libraries in all popular frameworks such as Java, .Net, Javascript, Erlang, etc. . It is based on the AMQP protocol and has several plugins that allow it to support STOMP and MQTT protocols as well.
RabbitMQ comes with a plug-in platform for custom additions, with a pre-defined collection of supported plug-ins, including:
- A “Shovel” plug-in that takes care of moving or copying (replicating) messages from one broker to another.
- A “Federation” plug-in that enables efficient sharing of messages between brokers (at the exchange level).
- A “Management” plug-in that enables monitoring and control of brokers and clusters of brokers.
Being light-weight, RabbitMQ fits both cloud and on premise deployments without adding much overhead.
RabbitMQ Architecture
RabbitMQ uses a dumb consumer — smart broker model, focused on consistent delivery of messages to consumers that consume at a roughly similar pace as the broker keeps track of consumer state.
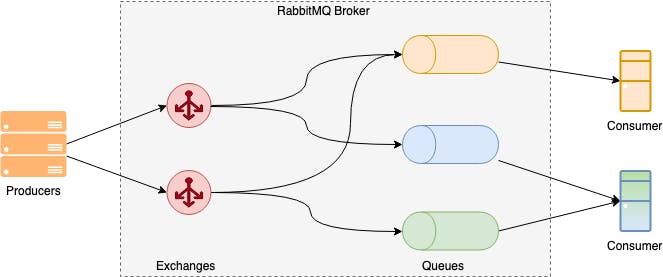
RabbitMQ supports both synchronous and asynchronous messaging needs. Publishers send messages to exchanges, while consumers retrieve messages from queues. Decoupling producers from queues via exchanges ensures that producers aren’t burdened with hardcoded routing decisions.
Using Docker to Deploy RabbitMQ
RabbitMQ is available as a docker image on Docker Store and comes in several versions, including Beta, with or without the management plugin. This article uses3.7.16-management for all further discussion.
Clone and Run the Image
$ docker run -d \
--hostname my-rabbit \
--name some-rabbit \
-p 0.0.0.0:5672:5672 \
-p 0.0.0.0:15672:15672 \
rabbitmq:3-management
This will start RabbitMQ, by default, on port 5672 and the management plugin on port 15672. Navigating to http://localhost:15672 will lead to the RabbitMQ Admin portal, which shows the overview of the network traffic, allowing the user to manage queues and exchanges.
Developers can also use rabbitmqctl, a CLI tool, to manage RabbitMQ, although running rabbitMQ on docker will require adding docker exec to the command.
Configuring Plugins
In order to configure plugins that will be initialised at run time, we need to mount the enabled_plugins file on the docker container.
The contents of the file enabled_plugins should look like:
[rabbitmq_management,rabbitmq_management_agent,rabbitmq_consistent_hash_exchange,rabbitmq_federation,rabbitmq_federation_management,rabbitmq_shovel,rabbitmq_shovel_management].
One important thing to note here is the Erlang file syntax, which dictates ending files with a ..
To make this file available within the docker container, it needs to be mounted as a volume while running the container as described by the -v environment variable.
docker run -d \
--name some-rabbit \
-e RABBITMQ_DEFAULT_USER=user \
-e RABBITMQ_DEFAULT_PASS=password \
-e RABBITMQ_DEFAULT_VHOST=/ \
-v enabled_plugins:/etc/rabbitmq/enabled_plugins \
-p 5672:5672 \
-p 15672:15672 \
rabbitmq:3-management
NodeJS-RabbitMQ Tutorial
1. Publish a message — send.js
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://user:password@localhost', function(error0, connection) {
if (error0) {
throw error0;
}
connection.createChannel(function(error1, channel) {
if (error1) {
throw error1;
}
var queue = 'dummy_queue';
var msg = 'Hello World!';
channel.assertQueue(queue, {
durable: false
});
channel.sendToQueue(queue, Buffer.from(msg));
console.log(" [x] Sent %s", msg);
});
setTimeout(function() {
connection.close();
process.exit(0);
}, 500);
});
2. Receive a message — receive.js
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://user:password@localhost', function(error0, connection) {
if (error0) {
throw error0;
}
connection.createChannel(function(error1, channel) {
if (error1) {
throw error1;
}
var queue = 'dummy_queue';
console.log(" [*] Waiting for messages in %s. To exit press CTRL+C", queue);
channel.consume(queue, function(msg) {
console.log(" [x] Received %s", msg.content.toString());
}, {
noAck: true
});
});
});
3. Sending and Receiving messages — node receive.js
Start the consumer — receive.js
node src/receive.js
[*] Waiting for messages in dummy_queue. To exit press CTRL+C
Publish a message on dummy_queue
node src/send.js
[x] Sent Hello World!
The consumer should log
node src/receive
[*] Waiting for messages in dummy_queue. To exit press CTRL+C
[x] Received Hello World!
Code examples in other popular languages are available on the official Github repo.
RabbitMQ in an E-Commerce application
Consider the following use case for an e-commerce website:
1. A customer makes a payment on the shopping site
2. Payment is confirmed, server generates invoice and sends the user an email.
3. Notifies the shipping company of the order.
4. Customer receives an email when the order is shipped
Why using RabbitMQ is valid for this use case:
1. Under extreme load, email generation could take longer than usual. It doesn’t need to be sent immediately, so adding it the the queue will ensure that this email will be delivered.
2. The shipping company could have a limit to the number of orders they can process. Publishing to the queue will ensure all orders are picked up and acknowledged.
3. Once the order is shipped, a message from the shipping department will notify the user of shipment.
RabbitMQ between Public Cloud and Private Cloud Zones
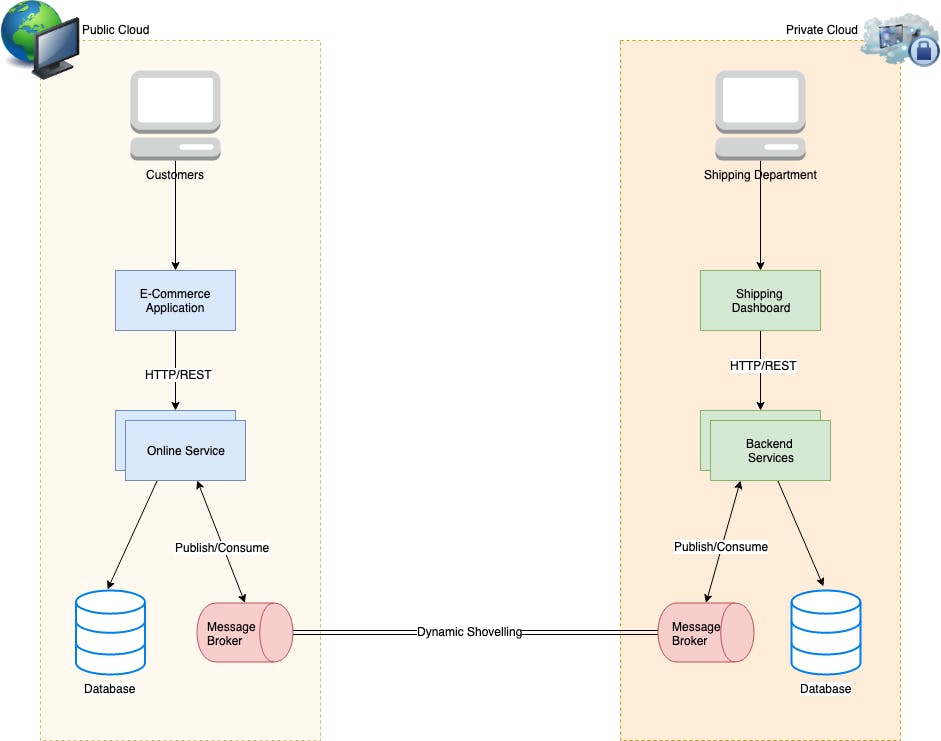
1. Customer places an order and the backend successfully processes the credit card payment.
2. Upon payment success, the server adds two messages to the queues send_email and shipping respectively with the order_id.
3. The send_email consumer receives the message and sends a PDF copy of the invoice to the customer.
4. Shipping department consumes the order from the shipping queue and initiates the delivery process.
5. Shipping notifies the shipping_initiated queue that the order has been shipping. Backend consumer watching this queue sends a shipping notification to the customer.
Queue Shoveling
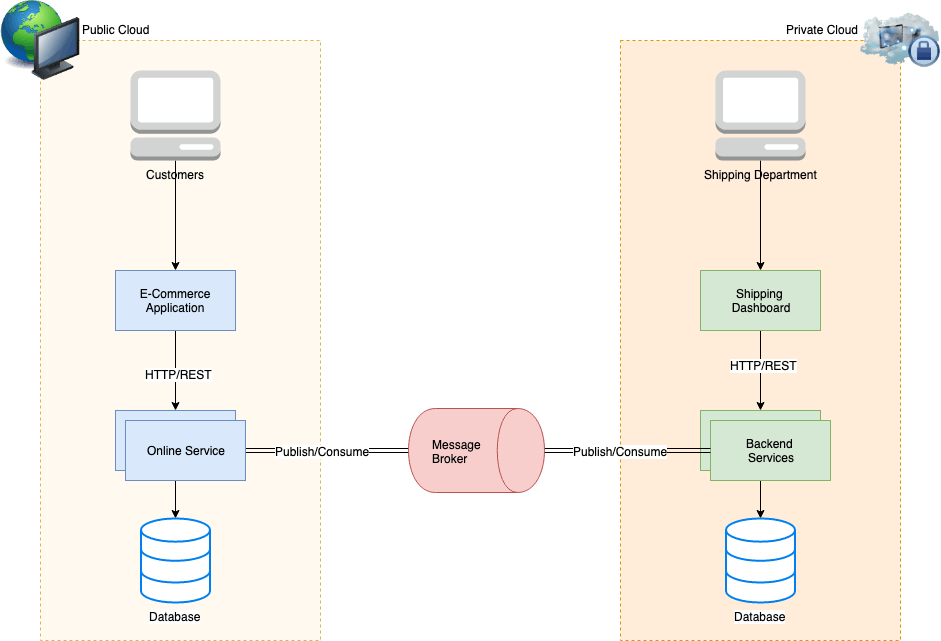
Consider the scenario of failure on the private cloud side. The entire machine hosting the application is lost and is out of service. Along with the application server, the RabbitMQ server also stops working. Customer orders placed in this situation will not be processed since the queue is dead.
In situations similar to the one described above, it is necessary to reliably and continually move messages from a source (e.g. a queue) in one broker to a destination in another broker (e.g. an exchange). The Shovel plugin on RabbitMQ allows you to configure a number of shovels, which do just that and start automatically when the broker starts.
The Shovel plugin is shipped with RabbitMQ and can be enabled while configuring RabbitMQ. Queue Shovelling can be configured both statically at run time and dynamically using the REST API or rabbitmqctl .
Dynamic Shovels
docker exec some-rabbit \
rabbitmqctl set_parameter shovel my-shovel \
'{
"src-protocol": "amqp091",
"src-uri": "amqp://",
"src-queue": "my-queue",
"dest-protocol": "amqp091",
"dest-uri": "amqp://remote-server",
"dest-queue": "another-queue"
}'
src-protocol and dest-protocol refer to the amqp protocol version being used on the source and destination queues respectively, either amqp091 or amqp10. If omitted, it will default to amqp091.
src-uri and dest-uri refer to the hostnames of the respective RabbitMQ servers. Similarly, src-queue and dest-queue refer to the source and destination queues on either servers.
For detailed documentation, please refer to the official documentation available at: https://www.rabbitmq.com/shovel-dynamic.html
Advantages of Shoveling
Loose coupling
A shovel can move messages between brokers (or clusters) in different administrative domains:
- with different users and virtual hosts;
- that run on different versions of RabbitMQ and Erlang.
- using different broker products.
WAN-friendly
The Shovel plugin uses client connections to communicate between brokers, and is designed to tolerate intermittent connectivity without message loss.
Highly-tailorable
When a shovel connects either to the source or the destination, it can be configured to perform any number of explicit methods. For example, the source queue need not exist initially and can be declared on connect (AMQP 0.9.1 only).
Supports multiple protocols
Starting from RabbitMQ 3.7.0, the shovel has support for multiple implemented protocols. They are AMQP 0.9.1 and AMQP 1.0. This means it is possible to shovel, e.g. from and AMQP 1.0 broker source to a RabbitMQ destination and vice versa. Further protocols may be implemented in the future.
A shovel is essentially a simple pump. Each shovel:
- connects to the source broker and the destination broker,
- consumes messages from the queue,
- re-publishes each message to the destination broker (using, by default, the original exchange name and routing_key when applicable).
With the addition of shovelling,
1. If the private cloud website (in this case the shipping dept dashboard) goes offline, customers can still continue to place orders which will reside on the public website RabbitMQ instance until being shovelled to the private cloud queue.
2. Similarly, when the internet website goes offline, customers will receive shipping notifications from the server whenever the service is back up.
3. Loose coupling between network layers.
4. Each RabbitMQ server can be upscaled and downscaled separately according to load.
5. Shovelling can be secured using TLS, thus becoming a secure exchange between two network.
In addition to shovelling, RabbitMQ also supports Clustering and Federation (both exchanges and queues) for developers to construct a more robust, distributed, and highly available RabbitMQ setup.
Clustering
As the name suggests, clustering is grouping multiple RabbitMQ servers to share resources and hence increase the processing power of the node. All data/state required for the operation of a RabbitMQ broker is replicated across all nodes. An exception to this are message queues, which by default reside on one node, though they are visible and reachable from all nodes.
Federation
The federation plugin allows you to make exchanges and queues federated. A federated exchange or queue can receive messages from one or more upstreams (remote exchanges and queues on other brokers).
To put it simply, the federation plugin allows transmission of messages in between queues without requiring clustering. This can give developers a more granular control over the performance of the system, as they can decide how to federate a high load queue.
Ina nutshell, adding a messaging layer to application architecture has the following high level advantages:
Increased Reliability
By decoupling different components by adding messaging layer to the application architecture, system architects can create a more fault tolerant system. Should one part of the system go offline, the other can still continue to interact with the queue and pick up where the system went off. The queue itself can also be mirrored for even more reliability.
Better Performance
Queues add asynchronicity to the application and allows for offsetting heavy processing jobs to be done without blocking the user experience. Consumers process messages only when they are available. No component in the system is ever stalled waiting for another, optimising data flow.
Better Scalability
Based on the active load, different components of the message queue can be scaled accordingly, giving developers a better handle on overall system operating cost and performance.
Developing (or Migrating to) Microservices
Microservices integration patterns that are based on events and asynchronous messaging optimise scalability and resiliency. Message queues are used to coordinate multiple microservices, notify microservices of data changes, or as an event firehose to process IoT, social, and real-time data.
Although the immediate disadvantage to migrating to a messaging architecture would be the loss of a synchronous request response mechanism because messaging introduces a slight delay in the publish/subscribe process, carefully planning and evaluating the needs of the system can help achieve the fine balance between the two.
References
1. Official RabbitMQ documentation
2. https://content.pivotal.io/blog/understanding-when-to-use-rabbitmq-or-apache-kafka